Evaluation
Code FREAK allows running automated evaluation on answers. An answer can be evaluation by a single or multiple evaluation step. Evaluation steps are independent of each other and are run in parallel to speed up the overall evaluation.
Each evaluation step can check things like:
-
Checking code for functional correctness (Unit Tests)
-
Analyzing code for common bugs (Static Code Analysis)
-
Checking code for proper formatting (Linting)
-
etc.
The actual content of the evaluation step (script) is up to the teacher. This allows using your favorite programming language and tools to check code. There are only a few things you need:
-
A command-line utility, which will test the code (e.g. junit, pytest, pylint, checkstyle, …)
-
The tool has to generate a report readable by Code FREAK. Please check out the list of supported report parsers.
Overview
Each evaluation can be split into three steps:
-
Preparing the isolated evaluation environment
-
Executing the evaluation script inside the environment
-
Parsing reports that have been created
All the steps will be run automatically by Code FREAK for each answer once configured by the teacher. Students can trigger evaluations as often as they like while the work on a task. Currently, there is no way to limit the number of tries for evaluations.
When preparing the evaluation environment, Code FREAK will create a new container on the server and copy over the files submitted by the user. Additionally, the evaluation script will be written to an executable file inside the container.
After the environment has been prepared the evaluation script is invoked. What exactly is done during this step depends on the content of the script. This may include running unit-tests or executing static code analyzers.
After the evaluation script has finished, Code FREAK tries to find one or more reports that have been generated by your evaluation script. If it cannot find any files we check the exit-code of the script: An exit-code greater than zero will mark the evaluation step as failed and will show the console output to the student. The console output will most likely contain the error thrown by the compiler and hints where you forgot to put a semicolon.
Evaluation Scripts
An evaluation script is a (Linux) Bash script that will be executed in an isolated environment to analyze the answer/code a student submitted. The simplest evaluation script could check for the pure existence of a file a student created, for example:
FILE=file.txt
if test -f "$FILE"; then
echo "$FILE exists, good job!"
exit 0
else
echo "$FILE does not exist!"
exit 1
fiIn this simple evaluation script the important part is the exit-code: Every exit-code greater than zero indicates a failure. The default report parser (see next section) will simply show the messages printed to the console to your students. To give more in-depth feedback to students you should utilize a testing framework or static analysis tool which can generate reports.
Report Parsers
Code FREAK internally uses a model called Feedback.
Each evaluation step generates a list of Feedback which helps student to improve their answer.
For example running "Pylint" with the appropriate parser will give the students a list of suggestions on how to improve the quality of their code:
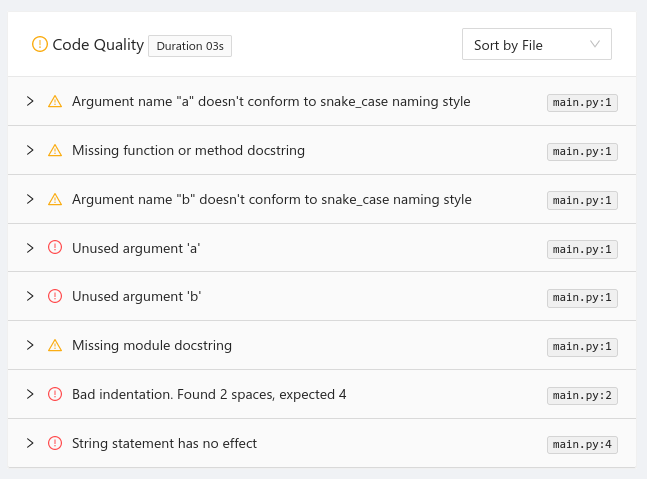
There are lots of well-established code analysers and testing frameworks available on the market.
In addition to printing found errors to the console most of them also allow generating so-called "reports".
Reports are machine-readable files with all issues that have been found by the specific tool.
For example ESLint or PHP_CodeSniffer allows printing there issues in more than ten different formats (see here and here).
Luckily, many tools share common reporting formats.
To parse all different formats into Code FREAK’s internal Feedback model we use something called "report parsers". Each parser tries to read one or multiple report files generated during evaluation and convert it into a list of Feedback. Below is a list of currently supported report parsers.
Supported Report Parsers
The list below contains a list of all supported report parsers and how they interpret files/output.
The name in braces after the parser name is the key/id of the parser which can be used in the evaluation step definition: Name of the Parser (key)
Default Parser (default)
The default report parser does not do any actual parsing but creates a single feedback entry which contains the output of the report file (or console). This can be useful if you are creating a new task and just finished your evaluation script to view the output of your script.
JUnit XML Parser (junit-xml)
Because each testcase can only be successful or failing the rules how we convert them to Feedback are quite simple:
-
Each
<testcase>will result in a single Feedback entry. -
The
nameattribute of each testcase will be taken as Feedback summary -
If the
<testcase>contains one or multiple<failure>entry it will be marked asfailedwith severitymajor. -
If the
<testcase>contains one or multiple<error>entries it will be marked asfailedwith severitycritical. -
If the
<testcase>contains neither errors nor failures it will be marked as successful.
The body of the feedback will either be taken from the message attribute if present or the body of the <failure|error> tag.
<testsuites>
<testsuite name="pytest" errors="0" failures="1" skipped="0" tests="2" time="0.016" timestamp="2021-08-06T12:34:02.621108" hostname="arch-desktop">
<testcase classname="main_test" name="test_function" time="0.000">
<failure message="assert 0 == 5 + where 0 = add(2, 3)">def test_function():
> assert add(2, 3) == 5
E assert 0 == 5
E + where 0 = add(2, 3)
main_test.py:8: AssertionError</failure>
</testcase>
<testcase classname="main_test" name="test_always_true" time="0.000" />
</testsuite>
</testsuites> Checkstyle XML Parser (checkstyle-xml)
-
Each
<error>entry will result in a single Feedback entry. -
The
messageattribute will be taken as feedback summary -
The severity will be mapped as follows:
-
ignoreto INFO -
infoto INFO -
warningto MAJOR -
errorto CRITICA
-
<checkstyle version="8.45.1">
<file name="/home/coder/project/src/main/java/Calculator.java">
<error line="2" severity="warning" message="First sentence of Javadoc is missing an ending period."
source="com.puppycrawl.tools.checkstyle.checks.javadoc.SummaryJavadocCheck"/>
<error line="4" severity="error" message="Line is longer than 100 characters (found 115)."
source="com.puppycrawl.tools.checkstyle.checks.sizes.LineLengthCheck"/>
</file>
<file name="/home/coder/project/src/main/java/Main.java">
<error line="13" column="5" severity="warning"
message="'method def rcurly' has incorrect indentation level 4, expected level should be 2."
source="com.puppycrawl.tools.checkstyle.checks.indentation.IndentationCheck"/>
</file>
</checkstyle> Pylint JSON Parser (pylint-json)
-
Each array-object will result in a single Feedback entry.
-
The summary will be read from the
messageattribute -
If the type is
conventionthe severity will be "minor", otherwise "major".
[
{
"type": "convention",
"module": "main",
"obj": "",
"line": 1,
"column": 0,
"path": "main.py",
"symbol": "missing-module-docstring",
"message": "Missing module docstring",
"message-id": "C0114"
},
{
"type": "warning",
"module": "main",
"obj": "add",
"line": 1,
"column": 8,
"path": "main.py",
"symbol": "unused-argument",
"message": "Unused argument 'a'",
"message-id": "W0613"
}
] Visual Studio Parser (visualstudio)
-
Each line will result in a single Feedback entity (if it matches the expected pattern; all other lines will be ignored silently)
-
If the type is "warning" the severity will be "minor", otherwise "major"
-
The summary will be read from the message content (everything after the second colon)
src/Calculator.h(1): error cpplint: [build/header_guard] #ifndef header guard has wrong style, please use: CALCULATOR_H_ [5]
Done processing src/Calculator.h
Total errors found: 1Environment Variables
When running the evaluation
| Variable Name | Example Value | Explanation |
|---|---|---|
|
|
The value is always "true". Indicates running in a CI environment. |
|
|
UUID of the answer currently processing |
|
|
UUID of the assignment currently processing. The variable might be empty if running in task-pool testing mode. |
|
|
UUID of the submission currently processing |
|
|
UUID of the task currently processing |
|
|
UUID of the user the answer belongs to |
|
Jane |
First name of the user the answer belongs to |
|
Doe |
Last name of the user this answer belongs to |
|
Username/mail address of the user this answer belongs to |